КНИГИ. Людвиг Петр — Победи прокрастинацию! Как перестать откладывать дела на завтра
Автор, чья фамилия вполне могла бы стать и именем 🤓, — это такой Максим Дорофеев из Пардубице 🇨🇿. В книге много похожего на Джедайские техники (мыслетопливо — энергия, принцип организации дел). Что уж говорить про оформление поясняющими схемами.
🤔 Кто у кого списал, не знаю. Но это и не важно, так как в различий в них больше, чем сходств.
😐 У Людвига написано менее подробно. Для кого-то это минус, для кого-то плюс.
🌐 В России у книги есть сайт http://www.pobedi-prokrastinatsiyu.ru/kniga/. На сайте в открытом доступе основные шаблоны по книге.
Краткий пересказ.
Вводная
Прокрастинация — это не лень (ты и не хочешь ничего делать) и не отдых (не предполагаешь ничего делать). Это состояние, когда тебе нужно что-то делать, но ты откладываешь.
✂️ Сегодня она усиливается «ножницами возможностей» — огромным спектром возможностей для использования нашего потенциала. Чем больше вариантов, тем вероятнее паралич решений.
Из информационного хаоса все сложнее вычленять информацию.
Победить прокрастинацию автор советует за счет системы из четырех компонентов.
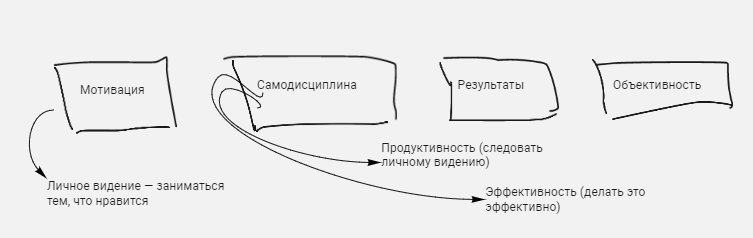
💪 Мотивация — хорошей мотивации можно добиться тогда, когда ты понял свое личное видение и твои действия сонаправлены ему.
🧐 Самодисциплина — набор приемов для наискорейшего движения по вектору, заданному личным видением. Сколько процентов времени мы тратим на действия, связанные с личным видением (продуктивность), и каких успехов за это время мы добиваемся (эффективность).
🏆 Результаты — эмоциональная и материальная отдача в результате действий.
🤔 Объективность — постоянная проверка своего уровня внешней средой.
1. 💪 Мотивация
Внешняя мотивация (кнут, пряник) работает, но плохо. Это нам известно уже по модели мотивации Сьюзан Фаулер.
Почему? Потому что человек делает не то, что хочет; у него не вырабатывается дофамин 💊, который серьезно влияет на творческие способности. Да еще и возникает чувство неудовлетворенности, которые человек переносит на окружение.
💰🥱 Но также неэффективна навязанная внутренняя мотивация целями 📈. Отлично, что вы представили цель, к ней стремились и выполнили: купили новую машину, дом, построили бассейн. Но после ее достижения возникает гедоническая адаптация — через неделю вы уже и не помните, как к этой цели стремились и ищите новую. До ее достижения вы несчастны.
🛣️ Решение — внутренняя мотивация пути. Это состояние, когда деятельность совпадает с личным видением. Автор приводит в пример компанию по производству инсулина Novo Nordisk. Все сотрудники компании от руководителей до швейцаров высоко замотивированы, поскольку занимаются важной для них работой — разработкой лекарств, спасающих жизнь.
Автор называет это состоянием потока 🌊. Хотя по Фаулер, поток — не лучшее состояние мотивации.
🦮 Может помочь так же ощущение смысла «эго-2.0» — итоги альтруистической деятельности: пожертвования, спонсорство, помощь и т. п.
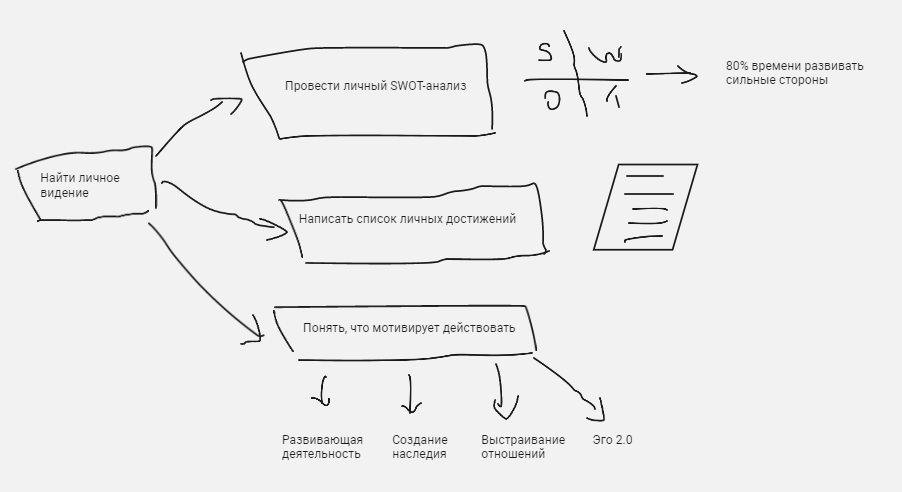
Как найти свое личное видение?
📋 1. Провести личный SWOT-анализ. Написать сильные стороны и посвятить 80% времени их развитию. Это поможет сократить ножницы возможностей.
🎖️ 2. Зафиксировать список личных достижений. Этот список покажет, чем вы гордитесь и соответственно что вас мотивирует. Таких достижений должно быть не менее 20.
🥳 3. Проанализировать мотивирующую деятельность. Постоянные действия в той области, которая воодушевляет, делают жизнь лучше. В каждой из областей минимум 3 вида деятельности, которой нравится заниматься.
— Развивающая деятельность
— Деятельность, создающее наследие
— Деятельность, помогающая выстраивать отношения
— Эго 2.0
🔭4. Создать бета-версию личного видения, ответив на вопросы:
— Какая любимая цитата? Какая идея резонирует с вашими мыслями сильнее всего?
— Три важные ценности в жизни.
— Чему вы хотите посвятить жизнь? Чем хотели бы заниматься в идеале?
— Какую пользу можете приносить обществу? Какая деятельность эго 2.0 под силу?
🔭👌 5. Личное видение — это несколько фраз или пунктов. ЭТО ПЕРВЫЙ ВАЖНЫЙ ШАГ, КОТОРЫЙ НЕ НУЖНО ПРОКРАСТИНИРОВАТЬ
💡💡💡 Лайфхаки для долгосрочной работы личного видения.
— 📋 Физическое воплощение, чтобы не забывать про него. Написать его на бумаге и периодически к нему возвращаться. Наш мозг забывает даже важные вещи. Мы не хотим, чтобы личное видение было забыто.
— 📜 Круто, если в этом воплощении будут дополнительные мотивирующие элементы, например, любимые цитаты.
— 🍥 Сосредоточение на процессе, а не на результате, чтобы избежать ловушки гедонической адаптации (лучше использовать формулировки типа «смысл жизни — делать...»).
— 🦮 Включить в деятельность элементы благотворительности Эго 2.0.
— ⚖️ Личное видение должно быть сбалансировано: место и самовыражению, и семье, и другим направлениям.
— ⚓ Дополнить якорями: физическими элементами (кольца, украшения, татуировки), взаимодействие с которыми будет напоминать о личном видении.
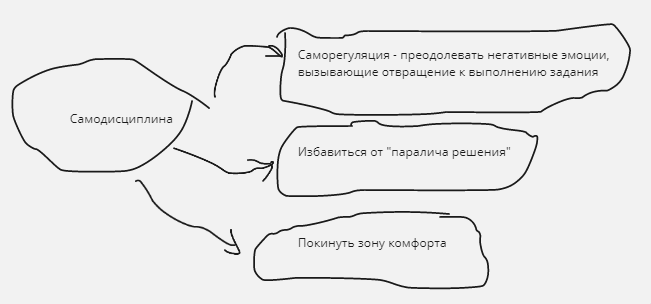
2. 🧐Самодисциплина
Тут три составляющие:
— 🧘Научиться саморегуляции
— 😨 Избавиться от паралича решений
— 🦸 Героизм
🧘 Как научиться саморегуляции?
Причина прокрастинации в известном строении мозга 🧠: предпочтение менее энергозатратным решениям на уровне лимбического мозга; проявление эмоций быстрее, чем проактивная реакция.
Мы управляем своим «слоном» благодаря «когнитивному ресурсу» 🔋 (~обезьяна и мыслетопливо у Дорофеева). Если этот ресурс истощен, за нас действует слон 🐘.
Когнитивный ресурс можно пополнять. Этому хорошо способствует:
— 🧃 питание, в частности глюкоза. Так, в загнанном состоянии можно выпить сока;
— 🤸 несложная физическая работа;
— 🚶♂️ прогулка.
Когнитивный ресурс важно расширять благодаря тренировке и решению задач и проблем. При их преодолении мы должны преодолевать паралич решений.
😨 Как победить паралич решений
Паралич решений возникает из-за того, что слон 🐘 боится высокой преграды 🚧. Основа преодоления этого паралича — снижение барьеров. После неоднократного повторения слон станет выполнять действия на автомате. Потом можно увеличивать постепенно барьер.
Тут важно постоянное повторение мелких задач, своего рода, тренировка.
Если мы прерываемся, например, перестаем бегать из-за болезни, то по возвращении стоит начать все с начала, то есть с минимальных уровней.
🍷 Вредные привычки — курение, алкоголь — такие же преграды, которые можно преодолевать постепенно ограничивая себя в них. Борьбу с ними можно усилить, если к вредным привычкам вызвать осмысленное отвращение: спрятать ярлык соцсетей глубоко в папку или платить окружающим за выкуриваемую пачку сигарет.
📜 Список-муштра для преодоления паралича решений
Набор приемов называется «список-муштра» — таблица итогов дня. Определяешь параметры, по которым будешь отслеживать прогресс, даешь метрику (например, алкоголь, не более 0,5 л вина в день). Начать лучше с 4-6 критериев. Лучше, чтобы они были согласованы с видением. Главное не ставить сразу слишком амбизициозные цели, чтобы слон не испугался.
Первая колонка всегда — самостоятельное выполнение «списка-муштры», т. е. фиксируешь сам факт заполнения списка. Сюда же можно добавить факт заполнения других инструментов (см. ниже): 🌊 списка-потока , 📋 списка to-do today.
Последняя — оценка потенциала дня по шкале от 1 до 10.
Если критерий за день выполнен, ставишь зеленую точку; если нет — красную. Если в строке есть хотя бы одна красная точка, то итоговая точка тоже красная. Иначе — зеленая.
Дополнения:
— синие точки — пропуски по объективным причинам. Например, из-за болезни не вышел на пробежку. Не злоупотреблять;
— определить главную задачу на месяц.
Пропускать дни можно не больше двух раз. В этом случае отчеркиваем предыдущий период и начинаем с «чистого листа».
😨 Паралич решения, причины
Помимо, того, что наш слон боится высокой преграды 🚧, паралич решения возникает еще из-за большого выбора 🔘 и недостатка саморегуляции 🧘. Непосредственно выбор чем заняться в течение дня — это очень ресурсоемкий процесс. Если стоит выбор между двумя важными делами А и B мы склонны перейти к неважной деятельности C.
Паралич решения заставляет отказаться от решения задачи в принципе.
📝 Исследования пенсионной системы США показывают, что обилие вариантов приводит к сокращению числа входящих в систему. Из пяти возможностей программу выберет 70% человек, из 35 возможностей — только 63%.
😞 Наличие опций также снижает удовлетворенность от принятого решения, поскольку всегда есть мысли об упущенной выгоде невыбранной альтернативы.
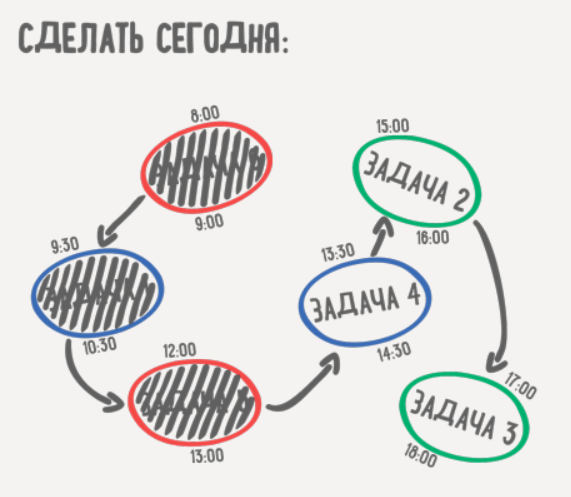
📋 Метод To-do today (сделать сегодня)
Решение проблемы паралича решений — метод to-do today. Его особенность в том, чтобы не использовать списки задач, но рисовать задачи в форме интеллект-карт.
Метод работает следующим образом:
— разместить на бумаге задачи и точно их сформулировать;
— каждая задача занимает от 30 до 60 минут. Маленькие задачи объединяй, крупные — разбивай;
— выделить цветом приоритеты: важные и срочные, важные несрочные, прочие (низкий проритет);
— определить путь, т. е. связать задачи между собой;
— наметить время выполнения каждой задачи;
— в момент выполнения задачи сосредоточиться только на ней;
— 🏁 каждую задачу доводи до логического завершения;
— 🔋 между задачами восстанавливай когнитивный ресурс;
— по мере выполнения задач вычеркивай их, в этом особое удовольствие;
— предусмотреть альтернативные пути, если решение задачи зависит от действий других людей.
Лучше лист дня с задачами готовить накануне. Его лучше включить в список-муштру.
📋📋 Метод To-do all (сделать все)
Полная экосистема для самодисциплины включает to-do today, а также следующие инструменты:
— ✔️ to-do — список задач не на повестке;
— 💡 ideas — то, что пока не задача, но о чем не хотим забыть;
— 📗 diary — ежедневник, в который заносишь задачи со сроками: встречи, мероприятия и проч.;
— 👨💼 управление, если задача кому-то делегирована.
Как это работает:
— подготовительный этап: на текущий день в to-do today заносишь задачи на день из трех источников: to-do, ideas, diary;
— если задача остается незакрытой, перемещаешь обратно в соответствующий список;
— автор рекомендует все делать на бумаге, собрать в одну прозрачную папку и поместить лист to-do today наверх;
— новые задания за день — распределяешь в соответствующий список;
— в списке to-do и управление задачам можно добавить сроки.
🧹 Систему надо периодически чистить.
Выходить за пределы, не соглашаться с толпой
Автор приводит эксперимент Зимбардо как иллюстрацию того, что мы склонны действовать вместе с толпой. Не всегда это правильно и полезно выходить за пределы зоны комфорта. В приложении к задачам — выполнить самую противную задачу с утра, посчитать себя 🦸 героем на оставшийся день.
3. 🏆 Результаты
Счастливые люди прокрастинируют меньше. Секрет счастья в том, чтобы достичь удовлетворенности и ее сохранить. Результат любого действия — материальная отдача и эмоциональная отдача (выработка 💊 дофамина).
Если мы долго не совершаем действий, погружающих нас в состояние 🌊 потока, это может «выбивать нас из колеи» и приводить к состоянию выученной беспомощности. Автор называет этот эффект 🐹 «словить хомяка» в честь эксперимента, когда после открытия крышки коробки 🐹 хомяк даже не пытается освободиться, наученный прежним опытом.
Способы борьбы:
— 🎲 техника inner-game (внутренняя игра), переключающая с негативного состояния на позитивное;
— 🌊 список-поток, поддерживающий в состоянии удовлетворения в течение долгого времени;
— 🐹 хомяк-перезагрузка для случаев, когда нужна полная перезагрузка системы личностного роста после серьезного выхода из колеи.
Как бороться с хомяком? Переориентироваться на будущее: несмотря на проблемы в прошлом и настоящем жизнь не закончена. Плюс переключить восприятие с негативного на позитивное через inner-game.
🎲 Метод inner-game
Это умение сознательно изменять 😥 негативные импульсы на 😐 нейтральные или даже 😀 позитивные. Для того, чтобы негативные импульсы не вызывали негативные эмоции. В эту игру можно играть в трех режимах:
— изменить восприятие 🤦♂️ неудачи. Неудачи — нормальный процесс в жизни людей, хотя современная культура навязывает обратное представление. На самом деле во время неудачи наш мозг выходит в зону обучения (learning zone), сама попытка — это признак 🦸 героизма;
— преодолеть превратности судьбы. Важно помнить, что успешен не тот, кто не падает, а тот, кто умеет быстрее ☝️ подняться;
— изменить восприятие прошлого с негативного на позитивное. Тут помогает написать список 🐹 «хомяков» и каждому последовательно задать вопрос — чем он был полезен и как продвинул вас вперед.
🌊 Метод список-поток
Метод основан на исследованиях М. Селигмана: ежедневное фиксирование трех позитивных событий. Кроме этого, отмечай по шкале от 1 до 10 свою удовлетворенность за день. Таким образом, мы формируем позитивное восприятие прошлого.
🐹 Метод хомяк-перезагрузка
Оставаться с хомяками на долгое время вредно. Действия по методу:
— 🐹Признать наличие хомяка.
— 🔋 Обновить когнитивный ресурс: выпить стакан сока, сделать несколько физических упражнений.
— Осознать, что хомяк тобой завладел.
— Признать, что причина в тебе.
— Заменить реакцию на импульсы с 😥 негативной на 😀позитивную.
— 🔮 Повысить ориентацию на будущее — напомнить себе, что нерационально оставаться с хомяком в то время, как задачи в области личного видения ждут.
— 🏺 Повысить ориентацию на прошлое — просмотреть список-поток и жизненные успехи.
— Мысленно отчеркнуть плохое настроение.
— 📋 Подготовить новый список to-do today, дополнив занятиями, которые приведут в состояние потока.
— 🦸 Совершить героический поступок.
4. 🤔 Объективность
Мы принимаем решения на основе наших 🧠 ментальных моделей — представлений об устройстве мира. Ментальные модели могут не соответствовать реальности, то есть быть необъективными.
Мы можем делать ложные выводы, например, из-за эффекта Даунинга-Крюгера: недостаток знаний не позволяет объективно оценивать свой уровень. Люди склонны защищать свои ментальные модели. В совокупности с этим эффектом ты начинаешь искать оправдания для ложных моделей.
Бороться с необъективностью полезно:
— 😎 объективная модель намного чаще ведет к лучшим решениям;
— 😟 необъективность затрудняет личностный рост;
— 🗡️ необъективность может нанести вред даже при добрых намерениях.
Методы повышения 🤔 объективности:
— 👨🎓 повышать компетентность с помощью образования;
— 👍 использовать качественные источники информации;
— ✋ стараться не выражать мнение по областям низкой компетенции или делать это аккуратно;
— ставить под сомнение свою интуицию;
— искать внешнюю обратную связь — выслушивать мнения окружающих и извлекать из него пользу;
— работать над критическим мышлением, то есть не соглашаться автоматически с идеями авторитетов;
— ⚡ искать опровержения также интенсивно, как подтверждения гипотез;
— 🪒 полагаться на бритву Оккама (наиболее вероятно самое простое объяснение);
— препятствовать коллективному эффекту Даунинга-Крюгера;
— часто источниками необъективности являются незыблемые догмы.
➕ Бонус. Сохранение результатов: встреча с самим собой
Мозг забывает даже самые важные вещи. Чтобы эффект от изменений не потерялся через некоторое время полезно делать 👥 встречи с самим собой.
На этой встрече полезно задать вопросы:
— Как далеко за последнее время ты продвинулся?
— Куда бы ты хотел двигаться дальше?
— Что еще было бы возможно улучшить?
А также оценить по шкале от 1 до 10 по отдельным практическим инструментам личного развития: 🔭 личное видение, 📜 список-муштра, 📋📋 система to-do all, 🦸 героизм, 🌊 список-поток, 🎲 внутренняя игра, 🐹 хомяк-перезагрузка, 👥встреча с самим собой.
Можно поставить конкретные задачи ко следующей встрече.