Польза от тепловых карт
Существует много типов диаграмм и различных способов отображения данных. Одни из них традиционные и, если вы их используете, у вас очень много шансов быть верно понятыми без лишних усилий и комментариев. Другие встречаются заметно реже. Однако с ними часто сложно рассчитывать на «понимание по умолчанию». Тепловые карты (heatmap) относятся к последним. Тем не менее, они имеют свою область применения и там очень эффективны.
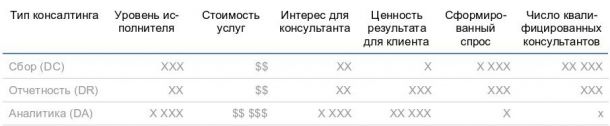
Недавно в газете Washington Post была опубликована точечная диаграмма. Каждая точка соответствует одному американскому городу, а ее положение — проценту белокожего населения (по горизонтальной оси абсцисс) и проценту белокожих полицейских (по вертикальной оси ординат). Цвет точек не имеет принципиального значения: синим цветом показаны те города, в которых процент белокожих полицейских больше процента белокожих жителей; серый соответственно, наоборот.
Проблема этого решения в том, что оно плохо отвечает на вопрос о плотности точек. Правый верхний угол: там сконцентрированы точки, и непонятно, сколько их. То есть: «Как много городов, в которых все полицейские белокожие (100% по ординате) и процент белокожего населения велик (70-100%)?». Эта проблема связана с излишней дисперсностью диаграммы: если какой-то показатель отличается у двух городов на 0,1% — это будут две, наезжающие друг на друга, точки.
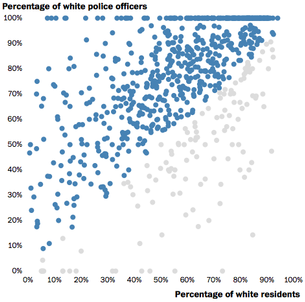
Решение проблемы — использование тепловой карты (heatmap): обе оси делятся на 5%-е интервалы, составляя тем самым 400 квадратов. Цвет квадрата показывает, сколько городов относятся к соответствующему диапазону.
Теперь, конечно, не увидеть каждый город, но возникает общее понимание ситуации, в том числе ясно, что концентрация показателей в правом верхнем углу значительна. В бледно-желтых квадратах — от 1 до 5 городов. Именно этот масштаб пока не дает полного представления, поскольку каждый пятый город имеет только белокожих полицейских.
Обратимся к содержанию статьи, которую иллюстрировала точечная диаграмма. Она посвящена резонансному для США событию: 4 апреля 2015 года в городе Норт-Чарлстон (Южная Каролина) белокожий полицейский из соображений самообороны застрелил чернокожего нарушителя. В Норт-Чарлстоне имеет место расовый дисбаланс: от общего числа жителей чернокожие занимают больше половины, однако среди полицейских преобладают белокожие (более 80%).
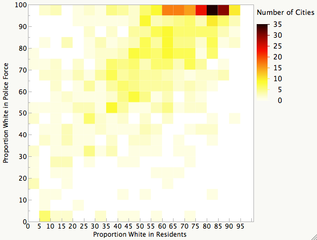
Это знание позволяет упростить диаграмму. Предположим, что в городах с большой долей белокожих в полиции (100%) расовый момент неприменим. Удалим соответствующие точки из выборки. Получается уточненная картина, дающая хороший вывод, — есть прямая корреляция между процентом белокожего населения и полицейских. Увеличивая масштаб по каждой из сторон клетки с 5% до 10%, получим следующий вид, отражающий прямую зависимость двух показателей.
Какие выводы можно сделать из данных Washington Post:
- Наблюдается определенная тенденция: процент белокожих полицейских выше процента белокожих жителей в населенных пунктах. При этом, конечно, есть исключения.
- Почти в каждом пятом городе полицейская служба состоит только из белокожих (на графике эти города не представлены).
- Стоит обратить внимание на города, которые сильно отстоят от среднего значения, т. е. в которых процент белокожих полицейских несравнимо выше процента белокожего населения и наоборот.
Еще один вывод: в некоторых случаях исключение отдельных сегментов данных (здесь — городов со 100%-й белокожей полицейской службой) не только не портит картину, но и дает ее лучшее понимание.
Пост основан на публикации в блоге Junk Charts.
Впервые опубликовано: blog.datasense.ru/view/polza-ot-teplovih-kart, 27 апреля 2015 года