
Приоритизация задач, историй
Общее про фреймворки проиритизации
🙄 Фреймворки приоритизации помогают. Они задают общие правила игры для команды и снижают напряженность из-за субъективных решений. Иногда и помогают зарабатывать :)
🤣 Но можно работать и без фреймворков, если команда не может договориться. Или каждая оценка получается неоправданно дорогой.
😡 Общие проблемы фреймворков:
— Субъективность оценок
— Сложность получения оценки требуемых ресурсов
— Взаимное влияние фичей и необходимость переоценки
👨🦲👨🦲👨🦲 Фреймворков много разных. Похожи они в том, что приоритет определяется важностью гипотезы/импактом и ресурсами на ее выполнение.
💡 И самое интересное. Фреймворки из трех, четырех, пяти букв обещают в названии, что для принятия решения будет достаточно такого же числа факторов: PIE, BUC, ICE — 3 фактора; RICE, RACE, REAN — 4 и т. д.
💡Однако, как потом выясняется, для оценки каждого из факторов нужно учесть еще кучу «подфакторов», чтобы дать точную оценку. Например, при оценка влияния Impact в RICE может быть сложена из оценки частоты использования фичи или ее уникальности для продукта; оценка простоты Ease — из простоты технической реализации и простоты согласования со стейкхолдерами.
💡В этом смысле «правильный фреймворк» — сразу выписать однозначно все метрики для своего бизнеса и идти по ним. Как Hotwire или PXL.
🤴 Особое внимание стоит уделить отличному от других подходу KANO.
Фреймворки приоритизации
1. «Риск допущения + Важность»
Мы закрываем первыми такие истории, которые позволяют проверить наиболее рисковые допущения и которые одновременно мы считаем важными для пользователей. Таким образом для каждой истории мы ставим оценку от 1 до 5 или 10 по двум критериям:
✔️насколько велик риск допущения, которое связано с историей. Риск допущения — это насколько велики будут отрицательные последствия для продукта в случае, если допущение окажется ложным
📝 Например, мы делаем систему хранения и обмена фотографиями. У нас осталось непроверенным допущение, что люди пожилого возраста будут пользоваться нашим облачным фотохранилищем. Мы рассчитываем на эту аудиторию, поэтому истории, в которой пользователь может использовать номер пенсионного удостоверения для скидки, дадим 10 баллов по допущениям
✔️насколько важна задача с точки зрения бизнеса, пользователей.
Суммируя две оценки получаем одно число. Чем оно выше, тем быстрее истории уходит в разработку.
2. BUC (Business, Users, Costs)
Метод BUC также дает одну оценку. Она складывается из трех факторов, которые оцифровываются по любой шкале (1-5, 1-10):
✔️ выгоды бизнеса: рост выручки, упрощение процессов, привлечение новых пользователей;
✔️ выгоды пользователей: удобство использования, дополнительный функционал;
✔️ затраты: насколько сложно историю закрыть.
В результате число получается сложением выгод и вычитанием затрат.
3. MOSCOW (Must, Should, Could, Would)
Этот метод впервые начали применять в 1994 году в Oracle.
Истории распределяются по четырем корзинам:
✔️ обязательно нужно сделать. Если историю не закрыть, последствия могут быть значимыми негативными.
✔️ следует сделать. Не самые важные требования, но которые стоит закрыть после обязательных.
✔️ могли бы сделать. Желательные требования, которые сделаем, если останутся ресурсы.
✔️ можем и не делать. Требования зафиксированы, но можно их отложить на следующий спринт, поскольку они не повлияют серьезным образом на бизнес или пользователей.
4. RICE (ICE)
RICE — пожалуй, один из самых популярных фреймворков приоритизации.
Критерии:
✔️ Reach (охват) — сколько пользователей охватывает гипотеза. Узкое место, что охваты приходится считать или оценивать. Это дополнительные деньги. Плюс охваты постоянно меняются — стоит договориться о периодах, на которые эти данные будут фиксироваться.
✔️ Impact (влияние) — как реализация истории повлияет на охватный сегмент (слабо-сильно). При выборе и оценке влияния удобно разложить «вклад» на составляющие.
📝 Примеры:
— является ли эта фича уникальной (можно ли решить пользовательскую историю сейчас иначе)?
— как часто будет использоваться?
✔️ Confidence (уверенность в результате). Значение уверенности можно определять: мнением PM, мнением HiPPO, групповой экспертизой, данными аналитики, опросом пользователей.
📝Можно договориться о шкале, например:
— сам придумал 5%
— команда согласна 10%
— есть запросы от пользователей, данные аналитики 30%
— опрос, кастдев 50%
— был успешный MVP или AБ-тест на другом продукте 70%
✔️ Effort (усилия). Проблема с оценкой усилий связана с тем, что это дорого и не всегда точно.
Конечная формула — в числителе производение R*I*C, в знаменателе — E.
Во фреймворке ICE все то же самое, кроме того, что не учитывается охват, а Effort может быть заменен обратной величиной Ease (простота). Финальную оценку получают перемножают трех множителей: I*C*E.
5. ⚡ HotWire, PXL
В компании HotWire есть своя шкала оценок. В ней 10 факторов, по каждому из которых оценка 0 или 1. Приоритет определяется простой суммой факторов. Факторы на 2015 год:
✔️ Влияет ли основную метрику (1 — новые бронирования на сайте/в приложении; 0 — любая другая вторичная метрика)
✔️ Что оптимизируем (1 — относится к результатам поиска или процессу биллинга)
✔️ Место (1 — если выше «fold», т. е. в верхней части страницы)
✔️ Охват (1 — распространяется на 100% всех пользователей)
✔️ Новизна (1 — новое на сайте; 0 — изменение существующих элементов)
✔️ Показало себя у конкурентов (1 — да, например, у Booking или Expedia)
✔️ Влияет на 2 или более улучшителя конверсии — conversion vein (1 -да). Примеры улучшителей конверсии: отображение цен и скидок, стимулирующие элементы (осталось часов до закрытия выгодного предложения), снижение затрат на регистрацию (гостевой логин), повышение доверия за счет логотипов систем безопасной оплаты
✔️ Относится к стратегической цели компании (1 — да)
✔️ Мобильность (1 — изменяется элемент мобильного приложения и/или повышает вероятность установки приложения)
✔️ Непрозрачные продажи (Opaque sales). Это специальная метрика HotWire, который продает не конкретные отели, а отель определенного класса. Пользователь узнает отель уже после оплаты, но при этом обычно получает хорошую скидку (1 — относится к метрике непрозрачных продаж)
Подробнее про систему HotWire
https://blog.optimizely.com/2015/05/05/how-to-prioritize-ab-testing-ideas/
https://www.navistone.com/blog/increase-your-online-sales-by-15-with-a/b-experiments
По аналогичной схеме конкретных вопросов построен более поздний фреймворк PXL. Отличие заключается в наборе параметров и в том, что оценка может быть как бинарной, так и не бинарной. Подробнее про систему PXL:
https://cxl.com/blog/better-way-prioritize-ab-tests/
6. REAN, RACE
Модель REAN разработана Стивом Джексоном (Steve Jackson) из компании Cult of Analytics. Она больше подходит для планирования маркетинговых активностей. В ней используются характерные стадии воронки:
✔️ охват (Reach),
✔️ вовлечение (Engage),
✔️ активация или целевая конверсия (Activate),
✔️ повторные покупки (Nurture).
RACE — почти брат-близнец REAN с той разницей, что в RACE активация относится к денежным показателям (в REAN — это могут быть просто конверсии или коэффициент конверсии). Эта модель — из The Smart Insights.
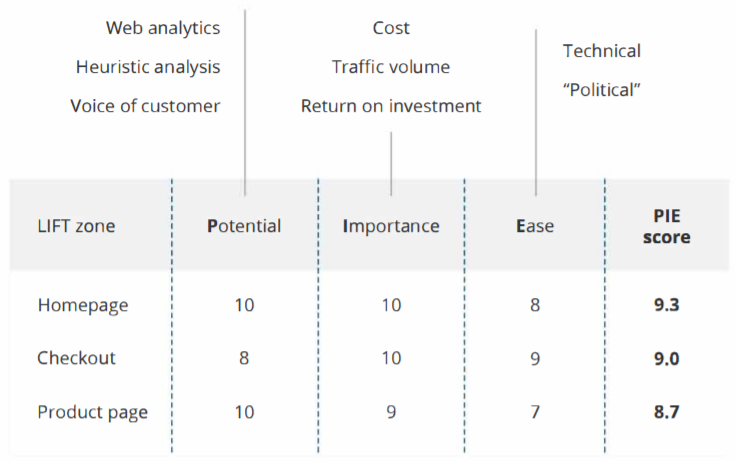
7. PIE
Фреймворк от Криса Говарда (Chris Goward), основателя WiderFunnel. Автор предлагает его использовать для приоритизации действий и гипотез.
✔️ Potential — насколько серьезным будет улучшение, насколько улучшиться релевантная метрика. Приоритет будет отдаваться таким действиям, которые кардинально меняют метрику. Вопросы, ответы на которые помогут оценить потенциал гипотезы:
— Подтверждена ли гипотеза данными?
— Подтверждена ли гипотеза обратной связью от пользователей?
✔️ Importance — насколько это повлияет на общую метрику. Если речь идет об оптимизации сайта приоритет будет у тех страниц, через которые проходит максимум трафика, приводящего к целевому действию. Вопросы:
— Повлияет ли главную метрику?
— Были ли раньше релевантные экспертименты и какие их результаты?
✔️ Ease — простота реализации
— Насколько легко проверить?
— Насколько простым будет согласование со стейкхолдерами?
8. KANO
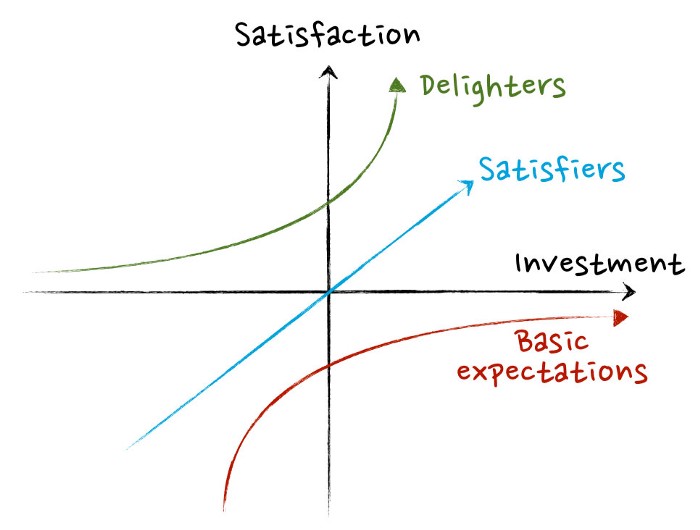
Фреймворк KANO назван в честь автора — Нориаки Кано (Noriaki Kano). Он основан на предположении, что в любом продукте есть 3 типа функций и отношений клиентов к ним:
✔️ Mandatory quality — обязательные свойства. В отеле обязательно должна быть кровать. В ресторане — официант для обслуживания гостей.
✔️ Desired quality — свойство, способное повлиять на оценку клиентов (как в положительную, так и отрицательную сторону). Это, например, площадь номера отеля: чем больше, тем лучше за прежнюю цену. Или скорость загрузки мобильного приложения.
✔️ Delightful quality — свойства, которые определяют положительную оценку, но если их не будет — ничего страшного. В номере отеля посетителя могут ждать приятные сюрпризы. Ресторан подает бесплатные снеки.
Интересно, что:
- Большая часть затрат на создание продукта связана с обязательными свойствами. В то время как на удовлетворенность способны сильно повлиять обычно дешевые «фишки».
- Но «фишки» быстро скатываются в первую корзину обязательных свойств, поскольку к ним пользователи быстро привыкают.
Как понять, к какой категории относится то или иное свойство? Для этого стоит задать два противоположных вопроса (прямой и обратный) с вариантами ответа.
📝Как вы отнесетесь к бесплатной бутылке воды в вашем номере?
— [x] Хотелось бы (Like)
— Так всегда бывает (Expect)
— Нейтрально (Neutral)
— Без этого не проживу (Live with)
— Мне бы это не понравилось (Dislike)
📝Как вы отнесетесь к тому, что в вашем номере НЕ БУДЕТ бесплатной бутылки воды?
— Хотелось бы
— [x] Так всегда бывает
— Нейтрально
— Без этого не проживу
— Мне бы это не понравилось.
На основании ответов по таблице соответствия можно понять суть свойства.
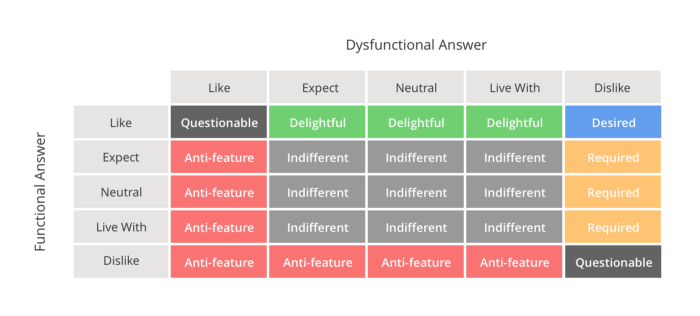
В нашем случае (прямой — Like, обратный — Expect) — это функция из третьей корзины, которую никто особо не ждет, но которая повысит удовлетворенность.
💡 Если у продукта несколько пользователей, то тип оценивается по паре ответов, которая встречала в опросе наиболее часто.